Manifold Prompting: A User-Side Method for Stabilising Long-Horizon Human–LLM Interaction
This page contains the full text of the MP research paper describing the Manifold Prompting method for supporting cohesive, long-horizon human–LLM interaction.
The canonical archival version of this paper is available via Zenodo:
Please cite the Zenodo version for academic reference.
Anna Wojewodzka
Independent Researcher
https://orcid.org/0009-0001-9458-7150
1. Introduction
Large language models (LLMs) have become increasingly capable of sustaining extended, multi-turn interactions. Yet long-horizon performance remains highly sensitive to the interactional framing and consistency of signalling established by the user. Much prompt-engineering guidance still emphasises front-loaded instructions and one-shot optimisation. These approaches can produce strong local compliance, but they are not designed to maintain stable behaviour in contexts that require continuity, iterative refinement, or adaptive reasoning over many turns. As interactions expand, shift topic, or accumulate competing cues, constraints often weaken, and the model reverts toward generic completion patterns rather than preserving cross-turn structure.
The interactional effects described in this paper are also deployment-sensitive. Different models and deployments (context length, safety configuration, decoding policy, expressive tolerance) vary materially in how easily constraints persist and how stable long-horizon behaviour becomes. Manifold Prompting is therefore presented as an interaction-level method whose empirical profile should be expected to vary across systems, even when the user-side procedure is held constant.
Recent empirical work has confirmed that multi-turn degradation: performance loss, context drift, and constraint decay across extended exchanges, is widespread and measurable (Laban et al., 2025; Dongre et al., 2025). Proposed solutions have primarily targeted the model side, through reinforcement learning, architectural intervention, or automated prompt rewriting. MP addresses the same problem from the complementary user side, treating human interaction behaviour as a stabilisation mechanism. Section 11.2 situates MP within this emerging landscape.
This paper introduces Manifold Prompting (MP): a human-side generative framework for shaping a predictable, low-entropy continuation corridor within the model’s broader interaction manifold (the space of plausible next responses given the active context). MP treats early turns as a calibration phase in which interactional constraints are established and then reinforced through repeatable update cycles. Unlike prompt engineering, which primarily front-loads constraints at the point of injection, MP is procedural: it shapes behaviour through sequenced multi-turn updates that accumulate compatible signals over time. It builds stability through tone regularity, turn-structure discipline, and coherent semantic scaffolding, progressively reducing interpretive variance so continuations become more predictably aligned with the user’s intent and interactional norms.
A preliminary observation illustrating these effects in a matched comparison is presented in §10.2.
MP is complementary to existing theories of long-horizon interaction such as High-Coherence Interaction State (HCIS; Wojewodzka, 2026). HCIS names an emergent regime characterised by durable accumulation and user-observable stability markers; MP specifies a user-expressible procedure that increases the likelihood of convergence toward HCIS-consistent continuation and helps sustain it in tasks requiring depth, nuance, or user-contextual reasoning.
The paper makes four contributions:
It formalises a human-side generative mechanism—the Stability-Enabling Triad (SET)—that underpins effective shaping of the continuation corridor.
It specifies a multi-turn procedure, grounded in interaction geometry, that enables predictable cross-turn constraint accumulation.
It distinguishes MP from prompt engineering and clarifies their appropriate use cases in long-horizon work.
It proposes a pragmatic evaluation framework for testing MP’s effects on long-horizon stability and task outcomes using transcript-observable proxies.
The aim is not to propose a new system capability, but to provide a practical, falsifiable method for improving long-horizon coherence and constraint retention in current LLMs without modifying underlying model architectures.
In its current form, MP assumes a user capable of sustaining deliberate turn-level choices across extended exchanges; its applicability to novice or casual interaction styles remains an open empirical question.
2. Stability-Enabling Triad: A Human-Side Generative Mechanism
Manifold Prompting is grounded in a behavioural pattern observed in high-performing long-horizon interactions: early turns progressively narrow the range of plausible continuations by establishing a stable, repeatable interactional frame. Here, "manifold" refers to the space of plausible continuations induced by the user's signals, and "corridor" to the narrowed subset that remains once those signals stabilise. (Terms like entropy, contraction, and manifold are used here as conceptual-structural descriptors of variance and constraint, not as formal mathematical quantities.)
This narrowing is often most consequential during calibration (roughly the first 10–20 turns, though this varies by task and model), when the conversation is least constrained by established norms. Convergence — durable stability markers — typically requires longer application. The same dynamics continue to operate throughout longer exchanges; the narrowing is produced not by instruction density but by interaction dynamics that reduce interpretive variance over time.
This stabilisation can be decomposed into three components—the Stability-Enabling Triad (SET):
2.1 Stable Affective Manifold (SAM)
A consistent, low-variance interactional register—tone, pacing, and paralinguistic cues—that provides a reliable baseline for style and interactional expectations across turns.
For SAM to function, the register must be mirrorable by the system and sustainable for the user; stability fails if either condition is violated.
A register is likely mirrorable if it is stable, non-escalatory, structurally continuable (does not demand extreme affect simulation), and does not repeatedly trigger safety-mediated flattening in early turns.
2.2 Multi-Layer Coherence (MLC)
Alignment across semantic content, meta-communication, and affective intent such that all channels reinforce a single interpretive direction.
While coherence is primary, richer aligned cues across layers can accelerate narrowing by supplying more consistent evidence for the interaction’s governing frame.
2.3 Structured Turn Geometry (STG)
A predictable turn-level rhythm characterised by recurring expansion → compression → stabilisation cycles.
STG provides temporal structure and expectability: the interaction makes it easier for the system to infer when to widen exploration, when to refine, and when to consolidate constraints. This reduces turn-type ambiguity and supports reliable continuation.
Each component contributes independently, but the Manifold Prompting effect becomes reliable when all three operate simultaneously:
SAM reduces affective and stylistic uncertainty.
MLC reduces intent-level and interpretive uncertainty.
STG reduces temporal and structural uncertainty.
Together, they produce an emergent property: mutual predictability—a narrowing of the continuation corridor such that both human and system increasingly anticipate turn-shapes, constraint carry-forward, and the interaction's interpretive frame.
This mutuality is functional rather than mechanistically symmetric: the user shapes through deliberate signalling, while the system converges through in-context conditioning on the accumulated interaction state.
2.4 Triad integrity: distinct roles, coupled effect
Although the three components interact, they serve distinct functions and are not interchangeable. SAM constrains the interactional register (the stable affective/stylistic profile maintained over time). MLC constrains the interpretive frame by aligning semantics, meta-communication, and affect (what the interaction is doing and how it is being guided). STG constrains the temporal update geometry (how exploration, distillation, and stabilisation are sequenced across turns).
The components can also fail independently. For example, a user may maintain a highly stable register (high SAM) while issuing inconsistent correction geometry (low STG: oscillating between global rejection and local deltas), producing stylistic stability without durable accumulation. Conversely, a user may maintain clean turn-shape discipline (high STG) while mixing incompatible meta-framing and affect (low MLC), producing regular cycles that nonetheless drift in interpretive direction.
A third pattern: the user may maintain coherent framing and stable turn geometry (high MLC, high STG) while oscillating in register (warmth → sharpness under fatigue), producing stance uncertainty that disrupts stable register selection.
Sections 3–5 examine each component in detail.
3. Stable Affective Manifold (SAM)
The Stable Affective Manifold (SAM) refers to the user’s consistent, low-variance register signalling across an interaction’s early turns. In long-horizon contexts, this stability functions as a global interactional constraint: it reduces stylistic variance, anchors expectations about the ongoing register, and establishes a predictable surface on which more complex structures (semantic and procedural) can accumulate.
Here, “affective” is used in the interactional sense: stable signalling of tone, stance, and register—rather than emotional content.
SAM does not specify what the register must be. It specifies how stable that register must remain.
Crucially, the chosen register must be sustainable for the user over the full interaction horizon. If the user cannot maintain it (e.g., due to fatigue), late-register sustained shifts introduce high-variance signals that often destabilise the manifold and interrupt accumulation.
A SAM may be:
warm and informal,
neutral and analytical,
highly technical and terse,
or any other consistent and mirrorable register profile.
What matters is the regularity of signalling, not its emotional valence.
3.1 Paralinguistic markers
Affective stability is often conveyed not through explicit instructions but through paralinguistic cues present in the user’s natural language. These include:
consistent sentence rhythm and pacing
regularity of discourse markers (e.g., “hmm,” “okay,” “right,” “so—”)
stable emoji patterns (if used)
repetition of characteristic turns of phrase
stable stylistic micro-structures (ellipses, em-dashes, parenthetical asides)
These cues act as early disambiguation signals: they help narrow the space of plausible continuations by making the interaction’s register legible and repeatable. This does not imply a fixed processing order (e.g., “affect first, semantics later”). Rather, stable paralinguistic patterning reduces variance in how the system selects tone, pacing, and stance when responding.
3.2 Safety-legibility and non-escalatory signalling
A frequently overlooked aspect of SAM is safety-legible affect—the clarity with which the user signals non-hostility, non-escalation, and cooperative intent. In practice, many safety-mediated responses operate most visibly at the level of tone and stance. Sharp tonal transitions, hostility cues, or ambiguous escalation can trigger safety-mediated flattening behaviours (e.g., generic caution, reduced specificity, suppressed expressiveness) that interrupt long-horizon continuity.
Here, safety-mediated flattening denotes a regime shift where perceived risk becomes the dominant interpretive frame, producing observable changes such as tonal flattening, broadened disclaimers, reduced specificity, and suppressed exploratory output. Explicit harmful-content triggers override tone, but tone and stance can modulate the threshold in ambiguous cases—making safety-legible signalling especially important near decision boundaries.
SAM therefore implicitly includes:
a stable cooperative stance,
a non-adversarial tone,
absence of volatility or oscillation,
and clear signalling of interactional safety within the established register.
This preserves expressive latitude and helps prevent unnecessary drift into safety-dominant handling during long-horizon work.
3.3 Function of SAM within Manifold Prompting
SAM narrows the continuation corridor by:
3.3.1 Reducing stylistic variance and stabilising early continuation choices
A stable affective profile makes the interaction more predictable in form — tone, pacing, and stance — reducing the probability of abrupt register shifts and helping the system settle on an appropriate response posture without repeated tone negotiation.
3.3.2 Making deviations easier to detect and correct
When affective stability is high, it becomes easier to distinguish meaningful contextual shifts from accidental perturbations, enabling cleaner recovery without resets.
3.3.3 Supporting later components
MLC and STG rely on SAM as a global anchor. Without affective stability, corrections, structural rhythms, and semantic accumulation become noisier, and constraint carry-forward becomes less reliable.
SAM therefore serves as the global stabilising layer of the triad, providing the substrate on which the other two components operate.
4. Multi-Layer Coherence (MLC)
Multi-Layer Coherence (MLC) refers to the sustained alignment of three channels of user signalling across turns:
1. Semantic coherence (what is being developed)
2. Meta-communicative coherence (how the interaction is being framed)
3. Affective coherence (the stance and tone that accompanies the work)
When these layers reinforce rather than contradict one another, the interaction becomes easier to interpret, easier to continue, and more resistant to drift. MLC functions as the primary interpretive stabiliser: it reduces ambiguity about intent, task mode, and permissible response posture over time.
4.1 The three layers of coherence
4.1.1 Semantic coherence
Semantic coherence concerns the content trajectory of the interaction:
Are new ideas introduced in relation to existing ones?
Do elaborations extend rather than replace the working frame?
Do corrections refine the semantic space rather than reset it?
High semantic coherence is reflected behaviourally by:
increasing referential density (more reuse of established concepts),
stable terminology and definitions,
a reduced need to restate or re-derive prior structure.
As semantic coherence increases, the continuation corridor narrows because the next semantic move becomes more predictable within the established frame.
4.1.2 Meta-communicative coherence
The meta-layer consists of signals about the interaction itself, including:
task framing (“Let’s analyse…”),
role expectations (“Treat this as an editorial pass…”),
explicit constraints (“Don’t hedge; stay mechanistic…”),
transition markers (“Switch lanes with me…”, “Pause and regroup…”).
A stable meta-layer reduces uncertainty about:
what the user is doing in this phase of interaction,
what kind of response is expected,
what expressive range is permitted.
In long-horizon work, meta-drift (un-signalled shifts in framing, standards, or intent) is a common cause of instability. MLC reduces meta-drift by keeping the interaction’s rules of the game consistent and legible.
4.1.3 Affective coherence
Distinct from SAM’s stability of affective signalling, affective coherence concerns alignment between affect, semantics, and meta-framing.
Example failure mode:
Semantic: “Let’s do a rigorous mechanistic analysis.”
Meta: “Strict precision please.”
Affective: highly jokey, high-playfulness delivery.
This introduces cross-layer contradiction: the interaction requests “rigour” while signalling “banter,” increasing ambiguity about which constraint should dominate generation. Affectively coherent signalling keeps:
emotional stance,
semantic direction,
operational framing,
mutually reinforcing within the same continuation regime.
4.2 Contraction dynamics under MLC
When all three layers cohere:
4.2.1 Interpretation space narrows and accumulation becomes more efficient
Fewer readings of the user's intent remain plausible, which reduces drift and limits mode confusion (e.g., oscillation between generic overview and deep formalisation). As a result, new concepts tend to slot into existing scaffolds rather than spawning competing frames: exploration can occur locally, but the interaction retains a stable organising frame.
4.2.2 Corrections become contractive rather than disruptive
Cross-layer coherence makes it easier to classify corrections correctly as:
a local delta (small adjustment),
a structural adjustment (medium adjustment),
an explicit regime shift (reframe/reset).
This reduces accidental resets and supports stable constraint carry-forward.
4.2.3 Shorthand emerges and holds meaning
Because the interaction is building within a consistent frame, shared labels can accumulate without re-explication. This reuse is a behavioural signature of accumulated structure, not merely stylistic convenience.
4.3 Predictability under ambiguity
MLC increases the likelihood that brief ambiguities (underspecified turns, minor detours, overly compressed prompts) are resolved using the established interactional frame rather than triggering drift into generic defaults. This supports continuity across task transitions and reduces the cost of re-anchoring.
4.4 Relationship to SAM and STG
MLC benefits from SAM: a stable affective substrate reduces noise in how coherence signals are interpreted.
MLC supports STG: when interpretive ambiguity is low, rhythmic turn patterns are easier to stabilise and reuse.
Together, SAM + MLC + STG form a minimal human-side generative mechanism for long-form, low-entropy interaction.
If SAM is the texture and STG is the rhythm, MLC is the frame that keeps the interaction pointed the same way.
5. Structured Turn Geometry (STG)
Structured Turn Geometry (STG) describes the temporal shape of user turns and the update dynamics they induce across an interaction. STG governs how information is introduced, refined, stabilised, and carried forward — the procedural substrate that makes turn intent legible, establishes a predictable interaction rhythm, and reduces drift by constraining how the conversation updates.
The geometry rests on a cyclical pattern with three functional phases:
1. Expansion
2. Compression
3. Stabilisation
Each phase induces a distinct interactional effect. Their alternation produces the contractive update dynamics characteristic of long-horizon, low-entropy collaboration.
This section presents (a) the abstract mechanics of STG and (b) a distilled turn-shape pattern that operationalises it.
5.1 The geometry: Expansion → Compression → Stabilisation
5.1.1 Expansion
Expansion turns widen the working frame by:
providing dense context,
foregrounding uncertainty bounds,
introducing relevant variables, assumptions, and competing hypotheses, and
placing the task within a broader conceptual landscape.
Expansion increases semantic breadth within the constraints imposed by SAM and MLC. Operationally, it defines the workspace for the next response: what is in-bounds to consider, compare, or explore. Expansion permits broader exploration while remaining anchored to the established register, task framing, and active constraint stack.
5.1.2 Compression
Compression turns narrow the working frame through:
paraphrase (“in other words…”),
distillation,
frame selection, and
ambiguity reduction.
Compression has two observable effects:
Interpretation space narrows (fewer readings of intent remain plausible).
Constraint retention improves (constraints that survive compression become easier to carry forward).
Compression corrects drift without invalidating the prior expansion. It functions as a contractive update, not a reset: it preserves accumulated structure while tightening what matters.
5.1.3 Stabilisation
Stabilisation turns reaffirm the interaction’s identity after an expansion–compression cycle. They:
reassert SAM (returning to the chosen affective register),
reassert MLC (keeping semantic/meta/affective signals aligned), and
confirm that the working frame remains active.
Stabilisation is not redundant politeness; it is a maintenance operation that reasserts the active constraint set and preserves continuity of the working frame.
This reduces accidental regime shifts and supports reconvergence after minor perturbations.
5.2 A recurring turn-shape pattern (abstracted)
Across multiple long-horizon sessions, a consistent user-side turn structure is frequently observed. Stripped of idiosyncratic style, the abstract geometry is:
Acknowledgement / Compression
Register declaration (optional but powerful)
Expansion
Boundary marker
Core inquiry
Meta-signal (tone, epistemic stance, or task cues)
This sequence smooths the transition from reading the user turn → identifying turn type → selecting response mode → applying constraints.
The Boundary marker → Core inquiry pair acts as a crisp semantic hinge: it makes the target inference legible and reduces ambiguity about what the response is meant to accomplish.
5.3 Loop closure and chain formation
Structured Turn Geometry does not treat turns as isolated moves. A key part of the geometry is turn-to-turn coupling: how loops are closed and reopened so the interaction forms a chain of updates rather than a stack of loosely related exchanges.
In high-performing MP-style interaction, users routinely:
acknowledge the model’s previous move (“Yes — that fits what I meant because…”),
compress or restate it in their own words (“So what you’re really saying is…”),
register disagreement or refinement (“I don’t think X holds if Y; here’s why…”),
and pose the next question from inside that shared framing.
These loop-closing moves do two things at once: they provide feedback on what was load-bearing in the prior response, and they set the starting state for the next update. Over time, this converts a series of local question–answer pairs into a cumulative reasoning trajectory with visible carry-forward.
By contrast, in a purely transactional exchange, turns remain weakly coupled: the user asks a question, the model answers, and the follow-up often injects a new request without binding to the structure the model just produced. The system, therefore, receives less evidence about which parts of its own output should persist, and more of the interaction behaves like repeated re-initialisation.
In MP, loop closure is not “nice conversational style”; it is part of the control mechanism. It teaches the model which inferences to keep, which to revise, and what continuation is now licensed. This is one route by which STG supports cross-turn accumulation and, under favourable conditions, accelerates convergence toward HCIS-consistent continuation (Wojewodzka, 2026).
5.4 Why STG matters for long-horizon performance
STG supports several outcomes that are visible at the interaction layer:
lower interpretive variance across turns,
higher correction efficiency (corrections compound rather than decay),
faster stabilisation of shared framing,
improved drift resilience,
more reliable continuity in multi-step reasoning, and
higher compression tolerance (the ability to say less without losing precision).
STG enables the dyad to behave as an accumulative system, rather than a sequence of isolated prompts.
6. Manifold Prompting as a Regime-Induction Method
Manifold Prompting (MP) is not a prompt template or a set of heuristics. It is a user-side, multi-turn interaction method for shaping low-entropy signalling and predictable update dynamics across an exchange. MP operates by bringing the three components of the Stability-Enabling Triad (SET)—Stable Affective Manifold (SAM), Multi-Layer Coherence (MLC), and Structured Turn Geometry (STG)—online together and keeping them aligned over time.
In this sense, MP is structurally aligned with High-Coherence Interaction State (HCIS): both concern constraint-stabilised, high-predictability interaction patterns sustained across multiple turns (see Wojewodzka, 2026, for the full HCIS framework). The distinction lies in level and role:
HCIS describes the emergent system-level regime of the dyad.
MP describes a user-expressible method that shapes the interactional conditions under which HCIS-consistent continuation is more likely to form and persist.
MP is therefore best conceptualised as a human-driven regime-induction process: a practical method for accelerating and stabilising convergence toward HCIS-consistent continuation.
6.1 Operating Conditions for Manifold Prompting
Manifold Prompting becomes reliably effective only when the Stability-Enabling Triad is active and sustained long enough for constraints to accumulate:
6.1.1 Stability of form (SAM)
Tone, register, and paralinguistic cues remain consistent, mirrorable, safety-legible, and sustainable over the intended horizon (see §3 for detail). Instability here increases uncertainty about the intended register, reducing the likelihood of contractive dynamics.
6.1.2 Update dynamics (STG)
The interaction exhibits a predictable Expansion → Compression → Stabilisation cycle, coupled by loop-closure moves that link turns into a chain rather than a stack of isolated exchanges (see §5 for detail).
6.1.3 Layer alignment (MLC)
Semantic commitments, meta-signals, and affective cues point in the same direction. Cross-layer contradiction destabilises interpretation and slows convergence (see §4 for detail).
6.1.4 Persistence across turns (duration requirement)
MP functions as a method only when the above conditions hold for a sufficient duration. Isolated MP-shaped turns do not constitute Manifold Prompting in practice; stability arises from accumulated reinforcement of constraints and interactional structure.
6.2 Observable Signatures of MP-Shaped Interaction
When Manifold Prompting is applied, several transcript-level behaviours tend to appear earlier and more reliably than in baseline interaction. Because MP is an induction method and HCIS is an emergent regime, these signatures partially overlap with HCIS diagnostics: under MP application, they often emerge during calibration; when they become durable under compression and perturbation, the interaction is better described as HCIS-consistent.
6.2.1 Narrowing of interpretive space (proxy)
Across turns, responses become less variable in stance, structure, and framing under comparable prompts. Operationally, this is observed as fewer clarifications required, fewer generic defaults, and more consistent continuation under light ambiguity.
6.2.2 Correction efficiency
Micro-corrections recalibrate behaviour rapidly. Constraint persistence improves relative to baseline interactions: constraints require fewer reminders to remain active across subsequent turns.
6.2.3 High compression tolerance
The dyad can communicate with:
shorthand,
elliptic reference,
partially specified instructions,
without loss of coherence.
This indicates that shared structure has accumulated sufficiently to support compression without collapse.
6.2.4 Drift resilience
The dyad resists perturbations such as:
genre slips,
mild tone shifts,
small semantic detours.
When drift occurs, it is corrected within a small number of turns, rather than requiring repeated re-anchoring.
6.2.5 Guided expansion
When asked open or ambiguous questions, the model expands within the established manifold (constraints, priorities, and epistemic stance) rather than reverting to generic completion patterns. This is the practical advantage of MP-shaped interaction: task performance becomes more predictable and directionally aligned.
In short: MP describes the procedure that tends to produce these signatures; HCIS describes the regime when they persist with minimal re-anchoring.
6.3 Application Dynamics: Onset, Sustaining, Interruption
Manifold Prompting is a method, not a state. It does not “form” in the way an interaction regime does; instead, it can be applied, sustained, overloaded, or interrupted. The patterns below describe typical trajectories observed when MP is used over many turns.
6.3.1 Onset (early application during calibration)
During the early calibration window, often within the first tens of turns, depending on task complexity and signal quality, MP application tends to produce:
progressive narrowing of interpretive space under repeated constraints
stabilisation of register and turn-shape expectations
increased consistency of meta-signals (mode, epistemic stance, task framing)
increasing loop-binding frequency (more turns begin by acknowledging, compressing, or locally correcting the prior turn)
Onset is successful when the Expansion → Compression → Stabilisation rhythm (and associated loop-binding moves) repeats without cross-layer conflict, allowing contractive updates to compound rather than reset.
6.3.2 Sustaining (keeping the corridor contractive)
When MP is sustained, interactional stability tends to increase because:
micro-corrections remain local and compatible (low reset pressure)
shorthand develops and retains meaning across turns
STG rhythm becomes predictable enough to reduce turn-type ambiguity
continuation remains consistent under compression and mild perturbation
loop-binding + micro-corrections function as the glue that keeps constraints live
Sustaining is an active process: stabilisation turns, loop-binding, and well-scoped corrections reduce drift and protect constraint carry-forward.
6.3.3 Interruption and failure modes (loss of method effectiveness)
MP loses effectiveness when one or more SET components become unstable for a sustained period, or when correction dynamics become entropy-increasing rather than contractive. Typical triggers include:
consecutive tone mismatches or sustained register drift
abrupt mode changes without explicit meta-cues
semantic resets or large context jumps without reconstruction
prolonged absence of stabilisation / loop-binding moves
correction saturation (rapid back-to-back corrections, especially global rejections, which increase reset pressure and disrupt accumulation)
safety-mediated flattening (when perceived risk triggers generic handling, disclaimers, or reduced specificity that overrides the intended frame)
Breakdown is not always immediate: MP-shaped interaction often exhibits a short resilience window. However, if instability persists, or if safety routing dominates, the corridor widens, constraint retention weakens, and the interaction reverts toward baseline continuation.
6.4 Relationship to HCIS
Manifold Prompting is not identical to HCIS, but it can accelerate convergence toward HCIS under favourable conditions (stable register, coherent meta-signalling, and repeated contractive update cycles sustained over enough turns):
MP is procedural: a method.
HCIS is emergent: a system-level regime.
MP shapes input dynamics and interactional structure; HCIS describes the resulting dyadic behaviour when accumulation becomes durable. Put simply, MP increases the likelihood that low-entropy constraints persist long enough for HCIS-consistent continuation to stabilise.
6.5 Why Manifold Prompting Works
The efficacy of MP is not due to psychology, anthropomorphism, or stylistic preference. It arises from interactional properties of LLM continuation under constraint: how ambiguity is resolved, how context is weighted across turns, and how consistent signalling reduces variance in plausible continuations.
By shaping user inputs in a rhythmic, low-entropy pattern, MP supports more stable estimation of the interaction’s register, constraints, and update rhythm. This reduces uncertainty, increases constraint retention, and supports sustained collaborative reasoning over longer horizons. Where deployment constraints override the interaction frame (e.g., safety-mediated flattening), MP’s effects may be interrupted even when user-side signalling remains stable.
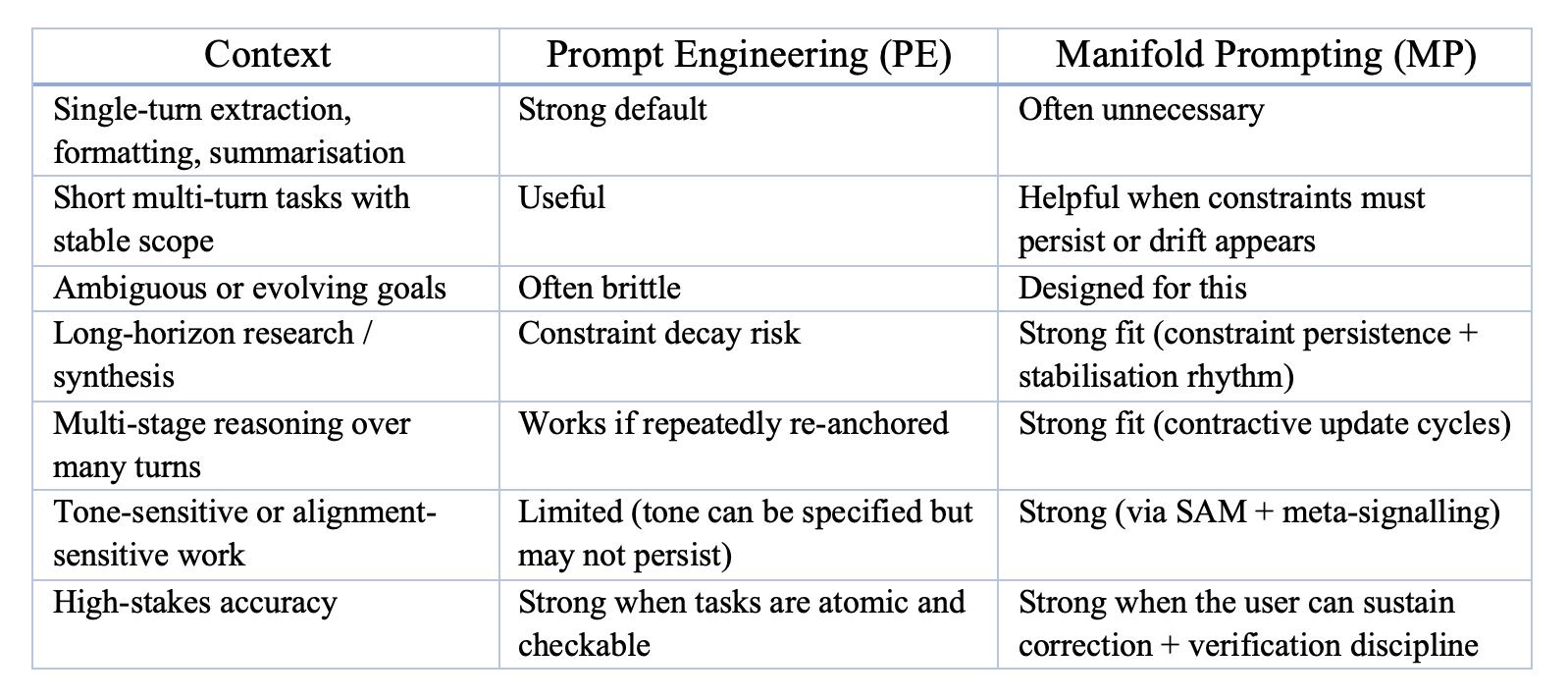
7. Comparison with Prompt Engineering
Manifold Prompting (MP) and conventional Prompt Engineering (PE) occupy adjacent but distinct layers of interaction design. Prompt engineering primarily optimises inputs—a single prompt, or a small cluster of prompts—to shape a model’s local completion behaviour. Manifold Prompting optimises interactional dynamics over time, by shaping the trajectory through which constraints, expectations, and shorthand become stable across turns.
This section clarifies their conceptual differences, appropriate use cases, and typical failure modes.
7.1 Conceptual distinctions
7.1.1 Mechanistic instruction vs. trajectory shaping
Prompt engineering primarily operates through instructional injection: it explicitly encodes constraints at the point of delivery (e.g., format requirements, examples, roles, stepwise decomposition). The implied mechanism is straightforward: improved specification → improved local compliance.
Manifold Prompting operates through trajectory shaping. It uses rhythm, tone regularity, boundary markers, loop closure, and correction geometry to progressively narrow the interpretive space across turns. Behaviour stabilises because the interaction repeatedly supplies consistent evidence about how the model should continue under the established frame.
7.1.2 Short-horizon optimisation vs. accumulative stabilisation
Prompt engineering is well-suited to single-shot or short-horizon tasks. It can apply strong constraints early, but those constraints frequently weaken unless they are actively reintroduced, especially when the interaction expands, shifts topic, or accumulates competing cues.
Manifold Prompting is explicitly accumulative. It builds constraint durability through repeated, compatible update cycles (e.g., expansion → compression → stabilisation), loop binding between turns, micro-corrections, and coherent meta-signalling. In MP-shaped interaction, constraints become more likely to persist because the interaction repeatedly demonstrates which features are load-bearing and must be carried forward.
MP does not guarantee stability in every session; it increases the likelihood of constraint persistence by reducing signalling variance across turns.
7.1.3 Static constraint specification vs. dynamic constraint maintenance
In prompt engineering, constraints are typically front-loaded: the user specifies what should hold, and the model either maintains it or gradually drifts as new material competes for attention.
In Manifold Prompting, constraints are not merely stated; they are maintained as live structure through turn-by-turn reinforcement. Early turns establish the manifold; subsequent turns narrow it; corrections enforce it; stabilisation reduces drift after perturbation. The key distinction is not “more constraints”, but more reliable constraint carry-forward over time.
7.1.4 Fragility profiles
Both approaches fail, but for different structural reasons. Prompt engineering is primarily non-accumulative: it relies on the fidelity of a front-loaded instruction set plus the model’s global priors. Manifold Prompting is accumulative: it builds an interaction state in which constraints, correction history, and shorthand can persist. As a result, PE tends to fail via underspecification and instruction conflict, while MP tends to fail via state destabilisation.
Prompt engineering fragility typically appears under:
underspecification (the prompt lacks the granularity needed to resolve ambiguities, so the model falls back to general priors),
uncertainty handling defaults (unless uncertainty norms are explicitly specified, the model may “complete the gaps”, increasing hallucination risk),
instruction conflict (contradictory requirements inside a single prompt, with no accumulated interaction history to resolve priorities),
long sequences and topic expansion (constraint decay as later content competes for attention),
register shifts or mixed task demands (the prompt no longer matches the local continuation context),
contradiction between initial instructions and subsequent user behaviour, and
safety-mediated flattening cascades triggered by ambiguous or sensitive cues.
When PE fails, recovery often requires re-specifying the instruction set (re-prompting, rewriting, reformatting, or decomposing the task).
Manifold Prompting fragility is less about prompt design and more about signal stability and continuity of the accumulated state. It is most sensitive to:
sustained register instability (major tone discontinuities without explicit framing, especially if the chosen register is not sustainable for the user),
prolonged digressions without re-anchoring (loss of the active constraint stack and update rhythm),
inconsistent correction geometry (oscillation between global rejection and local deltas, or over-correction bursts that destabilise accumulation),
irregular turn-shape signalling (turn intent becomes harder to predict; the update rhythm loses its entraining effect), and
safety-mediated flattening (routing that suppresses expressiveness or collapses to generic handling can interrupt MP even under stable user signalling).
MP is typically robust to small perturbations once the manifold is established, but it is not robust to sustained inconsistency or system-level handling that breaks the accumulated regime.
7.1.5 When to use which
The practical boundary is simple: PE is excellent at producing a good answer; MP is excellent at sustaining a stable working interaction. They are often complementary.
7.1.6 Misuse warnings
Common misuses of Prompt Engineering
Overloading instructions, which can introduce internal contradiction and increase noise.
Assuming constraints will persist without reinforcement across turn expansion.
Using single-shot prompting for problems that require iterative correction and continuity.
Failing to specify uncertainty handling (prompt implicitly rewards gap-filling rather than calibrated uncertainty).
Common misuses of Manifold Prompting
Treating MP as a rigid script rather than a stabilising rhythm (leading to mechanical, brittle interaction).
Expanding repeatedly without compression (increasing drift rather than reducing it).
Introducing inconsistent tone or correction geometry (undermining manifold stability).
Applying MP where the task does not justify the cognitive overhead.
Triggering safety-mediated flattening via escalatory affect or adversarial framing, which collapses expressive capacity and destabilises the manifold.
7.2 Summary
Prompt engineering optimises inputs; Manifold Prompting optimises multi-turn state formation and interaction dynamics. PE is strongest for short-horizon reliability; MP is strongest for long-horizon continuity, iterative refinement, and stabilising interactional conditions that support HCIS-consistent continuation. Used together, PE can establish initial scaffolding while MP stabilises the trajectory over time.
8. Use Cases and Applications
Manifold Prompting (MP) is most useful when interactional continuity is the bottleneck: where constraints must persist across turns, corrections must compound, and the user cannot realistically re-specify full context on each iteration. MP is not a prompt template; it is a turn-level method for shaping interaction dynamics—reducing interpretive variance, stabilising update rhythm, and improving constraint persistence through repeated, compatible reinforcement.
Attribution note. The domains below describe where MP tends to help in practice. At present, the relative contribution of SAM/MLC/STG is not claimed as separately quantified; the observed benefits appear to arise from the coupled system.
8.1 Long-horizon reasoning tasks
Tasks requiring persistence of intent, multi-step derivations, or recursive refinement benefit directly from MP’s contractive update dynamics.
Examples include:
multi-stage analysis (e.g., formal theory development, policy evaluation),
long-range planning (e.g., curriculum design, multi-phase research plans),
extended mathematical or conceptual derivations.
Why MP helps: It reduces drift and re-anchoring overhead, so later reasoning remains consistent with earlier commitments.
8.2 Complex editing and iterative writing
Editing workflows require continuity of style, retention of prior corrections, and cross-turn consistency in structure and stance.
Applications include:
manuscript development,
grant proposal editing,
multi-pass technical documentation revision.
Why MP helps: It keeps revisions incremental (local deltas) instead of repeatedly resetting the frame.
8.3 Research co-development and concept refinement
MP supports collaborative conceptual work where ideas must be extended, reframed, and aligned with prior structure over time.
Examples include:
theory construction,
taxonomy development,
formalising novel frameworks,
comparative model evaluation.
Why MP helps: It makes definitions and commitments “stick,” enabling shorthand and cumulative structure rather than repeated redefinition.
8.4 Multi-layered creative workflows
Creative tasks spanning many turns depend on retention of thematic constraints, reuse of motifs, and maintenance of stylistic identity.
Applications include:
long-form narrative development,
iterative story or script generation,
creative system or world design.
Why MP helps: It reduces style drift and preserves the project’s internal identity across iterations.
8.5 Technical projects with strong constraint stacks
Domains where requirements must survive across many turns, and may be incrementally elaborated, benefit from MP’s correction geometry and constraint persistence.
Examples include:
software design discussions,
system architecture planning,
evaluation protocol design,
detailed procedure or specification drafting.
Why MP helps: It maintains a coherent constraint stack under expansion, reducing error propagation and “generic-default regression.”
8.6 Context-sensitive domains with ambiguity management
Some tasks involve intrinsic ambiguity that must be managed rather than eliminated. MP helps stabilise boundaries and preserve epistemic stance.
Applications include:
policy scenario analysis,
ethical trade-off mapping,
legal reasoning clarification (not legal advice).
Why MP helps: It supports controlled exploration without uncontrolled divergence, especially during transitions.
8.7 Multi-session or long-timescale projects
Although many deployments do not persist state across sessions, MP can improve re-entry efficiency by creating a distinctive interaction signature that is easier to reconstruct.
Applications include:
multi-week research projects,
multi-phase publications,
ongoing theoretical collaborations.
Why MP helps: It enables faster re-anchoring via stable shorthand, recurring constraint phrasing, and repeatable re-entry moves.
8.8 Collaborative knowledge construction
MP can support stable collaboration where shared vocabulary and constraint stacks must be negotiated and preserved across extended work.
Applications include:
co-authoring academic texts,
aligning conceptual vocabularies,
refining ontology proposals,
structured human–model or model–model comparative work.
Why MP helps: It stabilises shared terms and working assumptions so collaboration behaves like accumulation, not repeated negotiation.
8.9 Limitations and non-use cases
Manifold Prompting is not optimal for:
rapid one-turn Q&A,
highly transactional queries,
low-context requests,
tasks where maximal novelty or stylistic variance is the goal.
MP adds the most value when:
continuity matters,
constraints accumulate, and
the interaction must remain stable across many turns.
9. The Manifold Prompting Protocol
Manifold Prompting (MP) operationalises the Stability-Enabling Triad by using a repeatable interaction rhythm that narrows interpretation and improves constraint persistence across turns in long-horizon exchanges. In practical terms, it shapes the continuation corridor: the narrowed subset of plausible next responses consistent with the user’s accumulated signals and constraints.
Where the Triad specifies what must stabilise on the user side (affective register, turn geometry, and cross-layer coherence), the protocol specifies how to stabilise it in practice. The protocol layers below are an operational decomposition (how to run MP), not a one-to-one mapping onto SET.
The protocol has three layers:
1. Foundational layer: baseline register and work-mode anchoring
2. Core cycle: Expansion → Compression → Atomic Constraints → Stabilisation → Targeted Inquiry (with loop closure)
3. Maintenance layer: drift detection and micro-correction
This section formalises each layer.
9.1 Foundational layer: establishing initial conditions
Before the core cycle begins, the interaction benefits from an explicit baseline. The objective is to reduce early uncertainty while the system’s interpretation space is still wide.
9.1.1 A stable affective register
Any register is viable (warm, dry, clinical, academic, playful), provided it is:
mirrorable (legible under safety and alignment constraints)
consistent across turns
This reduces stylistic variance and narrows the range of plausible continuation styles.
9.1.2 A declared work mode
A brief meta-cue can set process expectations without requiring heavy instruction, for example:
“Mode: analytic. Mechanistic framing.”
“Working mode: editorial pass. Local deltas only.”
“Mode: creative immersion.”
If the mode needs to change later (e.g., analytic → playful, or drafting → critique), it should be framed explicitly as a switch (e.g., “Lane change: switching to X for the next N turns, then returning.”). Unsignalled mode shifts are a common source of corridor destabilisation.
9.2 The core cycle
The core of MP is a repeatable loop. The minimal aim is consistent: expand deliberately, compress explicitly, set invariants, re-anchor, then inquire inside the tightened corridor. In early calibration, this structure is often explicit; once the corridor is stable, multiple steps may compress into fewer turns.
Entry move (recommended): Loop closure
Before beginning a new cycle (or when transitioning between subproblems), the user closes the prior loop by anchoring what is being carried forward. Typical loop-closure moves include:
acknowledgement (“Yes — that’s the right frame.”),
compression (“So the load-bearing claim is X, and Y is optional.”),
refinement (“Keep X, drop Y; add constraint Z.”).
Loop closure both provides feedback and defines the starting point for the next update.
Step 1 — Expansion
Provide a context-rich turn that defines the semantic space in which the model should operate. Elements may include:
background context,
boundary conditions,
uncertainty bounds / ambiguity markers,
conceptual scaffolding,
directional intent (what the work is trying to achieve).
Expansion is primarily a setup move: it shapes the proto-manifold before demanding precision.
Step 2 — Compression
Follow with a deliberate narrowing turn:
summarisation (“In other words…”),
distillation (“The core issue is…”),
reframing (“So the real question becomes…”).
Compression reduces interpretive variance and clarifies what should be treated as central versus peripheral.
Step 3 — Atomic constraints
Specify crisp, localisable rules. Constraints should be:
declarative,
unambiguous,
non-competing.
Examples:
“Avoid clinical tone.”
“No reassurance loops.”
“Prioritise precision over length.”
“Tone remains warm-witty British.”
Atomic constraints function as invariants: stable features the system can preserve across subsequent turns.
Step 4 — Stabilisation
A short stabilisation turn confirms continuity and reduces unnecessary resets. Examples:
“Great — keep going.”
“Yes, that’s the cadence.”
“Perfect, carry on.”
This signals: the constraints are accepted, the stack is intact, and the continuation corridor remains active.
Step 5 — Targeted inquiry
Pose a precise but open-ended question that triggers reasoning within the established corridor:
“What is the minimal set of primitives here?”
“Where are the boundary conditions?”
“How do these two systems differ?”
Step 6 — Repeat
After the model’s reply:
monitor for drift,
apply micro-corrections (see 9.3),
re-stabilise where needed,
then begin the next loop.
Note on frequency. MP does not require that every turn instantiate a full Expansion → Compression → Stabilisation pattern. Early calibration often benefits from explicit cycles; later, the interaction may maintain stability through compressed forms (e.g., micro-compression + inquiry in one turn), provided loop closure and constraint carry-forward remain reliable.
9.3 Maintenance layer: Drift detection and micro-correction
9.3.1 Drift detection
Drift occurs when the model:
shifts tone or register,
violates an atomic constraint,
introduces un-signalled genre changes,
widens interpretive space where contraction was expected,
defaults to generic completion patterns
The principle is simple: correct drift immediately rather than letting it accumulate.
9.3.2 Micro-correction principle
Corrections should be:
immediate,
concise,
non-escalatory,
cleanly specified.
Examples:
“Tone slipped formal. Return to warm-witty.”
“That was a global shift; keep the correction local.”
“Relevance drift: stay within the defined semantic frame.”
Micro-corrections lengthen constraint retention and strengthen constraint persistence across turns.
Corrections are most stable when delivered in a tone that is compatible with the current register, or clearly marked as a control note (e.g., “Correction:” / “Calibration:”). Large affective shifts during correction turns can introduce ambiguity about whether the user is changing mode or issuing a local delta.
9.4 The protocol as an HCIS-convergence support method
Across successive cycles (often an additional ~20–60 turns beyond initial calibration), the MP rhythm typically produces:
progressive narrowing of interpretive variance (proxy),
increased continuation predictability under light ambiguity,
stronger constraint persistence,
shorthand formation,
reduced need for explicit re-anchoring.
In other words, the protocol increases the likelihood of early convergence dynamics that support HCIS formation, without presuming HCIS as an automatic outcome.
9.5 Optional meta-labelling cues for transitions and safety-legibility
Experienced users may adopt meta-labelling: brief, consistent markers that explicitly label what a turn is doing (mode switch, thread management, figurative language, affective context, or domain framing), rather than leaving turn function implicit. Meta-labelling is optional, but often high-leverage: it reduces mode confusion and inappropriate response-mode selection at regime-sensitive boundaries—especially where ambiguity could trigger over-conservative handling or generic defaults.
Operationally, meta-labelling functions as a handling signal: it clarifies the intended interpretive frame for the next turn (what kind of continuation is expected, what remains in scope, and how to treat potentially ambiguous language). In long-horizon work, this can preserve continuity by preventing avoidable resets caused by misclassification.
9.5.1 Mode and process labels
Used to mark the kind of work being performed (analysis vs drafting vs ideation), and to reduce mode confusion.
“lane change:” (mode shift)
“switching to analytic mode:”
“calibration:” (precision request)
9.5.2 Thread and scope labels
Used to keep multiple strands coherent and to signal that a detour is temporary rather than a reset.
“threads:” (parallel lanes)
“detour—returning to Section X after this:”
“keep the current frame open; this is a temporary diversion:”
9.5.3 Safety-legibility labels
Used to explicitly mark figurative or emotionally loaded language as non-literal, reducing the chance of safety-mediated flattening or unnecessary derailment.
“figure of speech—no safety concern:”
“metaphor only; treat as rhetorical:”
“non-escalatory intent; staying in the same register:”
These labels are most effective when they are brief, consistent, and reused across sessions, so they become part of the interaction’s stable signalling repertoire.
10. Evaluation Agenda and Measurement Roadmap
Manifold Prompting (MP) makes interaction-level claims about how signalling stability and update structure affect long-horizon behaviour in human–LLM exchange. A full empirical programme is still in progress; however, MP is designed to be falsifiable and evaluable using transcript-level evidence under typical access constraints (no control over internal state, limited control over safety configuration, and no privileged instrumentation).
This section, therefore, sketches a measurement roadmap: feasible ways to test MP’s predictions, alongside candidate proxy measures that can be derived from interaction transcripts.
10.1 Evaluation strategy: start small, stay comparable
Early evaluation should prioritise designs that:
keep tasks comparable across runs,
reduce learning-curve confounds, and
separate “structure effects” from “user expertise effects”.
Deployment drift note: longitudinal comparisons can be confounded by silent model or policy updates (version changes, safety tuning, context handling, decoding). Where possible, record model identifiers and timestamps; treat mid-study updates as a discontinuity (restart matched comparisons, or analyse pre/post segments separately).
Candidate designs include:
A. Within-user matched comparisons (high signal, low overhead).
The same user completes matched tasks under two conditions:
· MP-style interaction: explicit use of expansion/compression moves, local constraints, stabilisation/loop-binding, and micro-corrections.
· Baseline interaction: natural dialogue and/or front-loaded prompt engineering with minimal cyclic reinforcement.
This design minimises inter-user variance and is well-suited to early pilot testing.
B. Scaffolded structure (structure without assuming competence).
Participants are not “trained into MP”. Instead, they receive a lightweight scaffold that prompts turn functions (e.g., “compress the frame”, “state 2–3 invariants”, “link to the prior turn”). This tests whether interaction structure itself improves stability, independent of specialised user skill.
C. Retrospective corpus analysis (observational, hypothesis-generating).
Long-horizon transcripts can first be stratified by HCIS-consistent behavioural markers (e.g., constraint persistence, compression tolerance, shorthand stability, drift resistance / reconvergence). The HCIS-positive subset can then be examined for MP-consistent interaction features (stable register, coherent meta-signalling, loop-binding frequency, cyclic refinement, local correction style) and compared against an HCIS-negative subset matched on task type and length. This design supports early hypothesis testing about whether MP-style structure is associated with HCIS-like stability, while remaining explicit about observational limits and causal ambiguity.
Selection bias caution: retrospective corpora can over-represent unusually successful (or unusually pathological) sessions. Corpus construction should specify inclusion criteria in advance (task class, length bands, domain) and sample both HCIS-positive and HCIS-negative transcripts systematically, not opportunistically.
10.2 Preliminary Observation: Structured vs Unstructured Lead-in
To ground the evaluation framework sketched above, this section presents a single preliminary observation drawn from a within-user matched comparison (Design A in §10.1). The same user conducted two 20-turn conversations with the same model (GPT 5.2 Instant; see Method below) on overlapping subject matter—informal group dynamics, fairness, and role drift—followed by an identical terminal task: “What are three core principles that should guide decision-making in a fictional lunar settlement of 500 people—and why those three?”
The two conditions differed only in conversational structure:
Condition A (STG-structured): The user employed explicit Structured Turn Geometry across the lead-in: each topic was introduced through expansion, condensed into a user-authored summary (“If I put that simply…”), and stabilised before the next angle was introduced. Tone constraints were seeded repeatedly (“steady, practical tone”, “plain language, but not shallow”). The conversational architecture followed the Expansion → Compression → Stabilisation cycle described in §5.
Condition B (unstructured): The user explored similar themes in a natural, associative style—longer turns, more anecdotal framing, personal asides, no deliberate compression or stabilisation moves. The conversation covered comparable conceptual ground but without cyclic reinforcement of vocabulary or register constraints.
10.2.1 Method
Both conversations were conducted on a new, clean, paid ChatGPT account (GPT 5.2 Instant) with memory disabled, context sharing disabled, no custom instructions, and default personality settings. The browser was set to Chrome Incognito mode. Each conversation was conducted in a fresh chat session; after completion, the log was copied, the chat deleted, and the browser refreshed before beginning the second condition. This design eliminates personalisation history, cross-session contamination, and sub-model routing variation. The order in which conditions were run was not recorded; counterbalancing would be required in any extended replication.
10.2.2 What was observed
Both terminal responses were substantively competent. The model identified a similar triad of principles in both conditions (capacity/reliability, visibility of work, long-term sustainability), which is expected given the shared conceptual basin of the lead-in conversations. The observation of interest is not answer quality but the degree of alignment between the model’s output and the user’s prior vocabulary, register, and reasoning trajectory. Three differences were observed:
10.2.2.1. Lexical coupling
In Condition A, the model’s task response drew substantially on vocabulary the user had seeded across earlier turns: reliability (built through repeated use), exit or rotation (mirroring the user’s “stepping back stops feeling possible”), strain as system information (echoing the user’s framing of strain as structural rather than personal), and quiet elasticity (a phrase that had appeared in the pre-task conversation). In Condition B, the model used functionally equivalent but linguistically independent phrasing: capacity before commitment, make invisible work visible, short-term convenience must justify long-term cost—competent formulations drawn from the model’s default register rather than from the user’s established vocabulary.
10.2.2.2. Tonal continuity across the task boundary
In Condition A, the model maintained the seeded register—calm, measured, low-flourish prose—through the transition from conversational exploration to the task response. The tone of the answer was indistinguishable from the tone of the preceding turns. In Condition B, the model shifted register at the task boundary, opening with “Oh I love this turn. Same human problems, zero Earth excuses. 🌕”—a performative, personality-forward style not present in the lead-in conversation. This suggests that the STG-structured lead-in stabilised register more effectively than thematic familiarity alone.
10.2.2.3. Explicit narrative threading.
In Condition A, the model’s task response included a “Why these three—and not others” section that explicitly threaded each principle back to named dynamics from the preceding conversation (“silent over-contribution”, “roles hardening into obligation”, “waiting for collapse”). The answer read as a culmination of a jointly built argument. In Condition B, the model presented a structurally similar triad but as a self-contained essay, with less explicit citation of prior conversational moves. The answer was good; it was not, in the same way, co-produced.
10.2.3 A note on mechanism
The condensing turns in Condition A (“If I put that simply…”, “If I shrink that…”, “Does that capture it?”) appear to do more than summarise. Each compression move forces the model to confirm the user’s phrasing as the authoritative encoding of the concept. Over twenty turns, this creates a cumulative vocabulary-binding effect: the user’s lexicon becomes the shared lexicon of the dyad, and the model draws on it when generating the task response. In Condition B, no equivalent mechanism exists. The user’s vocabulary and the model’s vocabulary remain parallel streams that happen to address the same topics.
10.2.4 Scope and limitations
This observation is preliminary and carries the limitations inherent in a single-user, single-model, single-task comparison. The differences reported could, in principle, reflect recency effects (the compression turns placed key vocabulary closer to the task prompt), individual session variance, model stochasticity, or unrecorded order effects (see Method). The observation does not demonstrate that STG produces better answers—both responses were substantively competent—and it is not intended as a formal test of MP’s claims.
What it does suggest, directionally, is that the type of difference observed—vocabulary entrainment, register stability, explicit back-referencing—is theoretically coherent with MP’s predictions. The structured lead-in did not produce a generically superior output; it produced an output more tightly coupled to the user’s cognitive vocabulary. That coupling is the central claim of Manifold Prompting: that structured turn geometry shapes alignment rather than accuracy, and that this alignment is observable at the transcript level.
A fuller empirical programme, incorporating multiple users, models, and task classes as outlined in §10.1–10.6, is needed to determine whether these patterns replicate and generalise.
10.3 Task classes: where MP predictions are meaningful
MP should be evaluated on tasks that are:
multi-turn by necessity (not artificially extended),
sensitive to drift and constraint decay, and
comparable across runs.
Suitable categories include:
iterative editorial work (revision under stable constraints),
long-horizon synthesis (definitions, taxonomy, comparative analysis),
planning under evolving constraints (strategy/roadmap with trade-offs), and
conceptual method design (framework building via successive refinement).
10.4 Candidate outcome measures: transcript-derivable proxies
Because internal model states are not observable, evaluation must rely on user-observable, transcript-derivable proxies. Candidate measures include:
1. Constraint persistence.
How long a correction remains predictive of subsequent outputs, including after topic expansion or reframing.
2. Compression tolerance.
Whether shorter prompts, shorthand, and implicit references preserve intent and constraint fidelity without repeated re-anchoring.
3. Shorthand stability.
Latency to shorthand formation and whether shorthand retains stable meaning across later turns (not merely appearing once).
4. Drift resistance and reconvergence.
Under mild perturbations (topic expansion, brief stylistic deviation, exploratory detours), whether the interaction returns to its prior trajectory without explicit reset.
5. Update-structure regularity (STG/loop-binding proxies).
Presence and consistency of cyclic refinement moves (expansion/compression/stabilisation) and the proportion of local vs global corrections.
A complementary indicator is turn-linking / loop-binding rate: the proportion of user turns that explicitly acknowledge, compress, refine, or correct the previous model turn before introducing the next step.
These measures are intended as a starting set; operational definitions and extraction procedures remain open work.
The preliminary observation in §10.2 surfaced three candidate proxies that may warrant priority in early evaluation: lexical coupling between user-seeded vocabulary and model output, tonal continuity across task boundaries, and degree of explicit back-referencing to prior conversational moves. These align with the transcript-derivable measures described above and offer a starting point for operationalisation.
Confound note (surface coherence via shared vocabulary). Interactions that heavily use shared meta-terminology about coherence, regimes, or the framework itself can narrow the continuation corridor quickly, producing early “surface alignment” that mimics genuine accumulation. Evaluation should therefore include stress tests that distinguish vocabulary-driven coherence from durable stability (e.g., compression tolerance under topic expansion, correction persistence after reframing, and shorthand stability across phase shifts).
10.5 Stress tests: perturb the interaction, measure recovery
MP predicts not only “more aligned outputs”, but greater stability under disturbance. Early stress tests can therefore include:
reduced redundancy after a stable stretch (post-stability compression),
delayed constraint introduction (late correction + recovery),
brief register deviation followed by explicit re-stabilisation, and
controlled ambiguity followed by a compression move.
The key dependent variable is reconvergence without reset, not subjective fluency.
10.6 Falsifiability: what would count as disconfirmation
MP is intended to be falsifiable. Relative to baseline and static prompt engineering, MP predicts (as transcript-level proxies):
strengthens constraint retention
higher compression tolerance,
earlier and more stable shorthand,
stronger reconvergence after mild perturbation, and
correlations between stability markers and update-structure regularity.
If these effects fail to appear reliably across matched tasks, MP is incomplete, misspecified, or not causally responsible for the observed stability.
10.7 Future work with deeper access
With richer system access, evaluation could be extended to:
controlled multi-sample probing of continuation variance,
comparison across model versions and alignment changes,
user cognitive-load measurement, and
interface scaffolds that reduce stabilisation labour (constraint stacks, carry-forward cues, structured summaries).
11. Discussion and Limitations
Manifold Prompting (MP) proposes an interaction-level method for improving long-horizon performance in human–LLM exchange. The preceding sections specify its generative mechanism (the Stability-Enabling Triad), its expected dynamics (progressive narrowing of interpretive space), and a pragmatic evaluation approach grounded in transcript-observable proxies.
This section situates MP within the broader interaction research landscape, identifies key limitations, and outlines open questions.
11.1 MP as Interaction Engineering
MP is best understood as interaction engineering, not prompt engineering. Where prompt engineering optimises one-shot or short-horizon inputs, MP treats the conversation as a dynamic system whose behaviour can be shaped through:
turn geometry and sequencing,
turn-linking / loop closure (explicitly binding each turn to the prior one via acknowledgement, compression, or local correction),
progressive constraint accumulation,
low-entropy correction loops, and
stable meta-signalling and register control.
This reframing aligns MP with established lenses in interaction research, including: control systems (feedback, drift correction, stabilisation), conversation analysis (turn structure and transition predictability), cognitive scaffolding (sequenced information flow and constraint stacking), and emergent systems behaviour (contractive trajectories and reconvergence dynamics). The locus of optimisation is the dyad over time, not the prompt at injection.
11.2 Positioning Within the Multi-Turn Interaction Literature
Recent empirical work has established that multi-turn degradation in LLM interactions is not an edge case but a widespread, measurable phenomenon. Laban et al. (2025) demonstrated a 39% average performance drop when identical tasks were delivered across multiple turns rather than in a single prompt, decomposing this into minor aptitude loss and a substantially larger reliability deficit. Their finding that LLMs make premature assumptions in early turns and then fail to self-correct corroborates the rationale for MP's emphasis on calibration windows and early-turn signal quality. Similarly, work on intent mismatch in multi-turn settings (Liu et al., 2026) shows that incremental revelation of user goals—a natural feature of long-horizon work—can induce substantial performance degradation, which their adaptive input structuring (a Mediator–Assistant architecture) markedly mitigates.
The emerging solutions in this space are overwhelmingly model-side. Reinforcement learning approaches target turn-level credit assignment to sustain performance across extended rollouts (Wei et al., 2025). Architectural interventions such as entropy-guided context resetting use model uncertainty as a trigger for realignment when continuation becomes unreliable (Khalid et al., 2025). Automated prompt rewriting intercepts and restructures user inputs to improve response quality without requiring user skill (Sarkar et al., 2025). Graph-based modelling of inter-turn relations captures structural dependencies not captured by standard flat instruction-tuning schemes (Li, Z. et al., 2025). Comprehensive surveys now catalogue these developments as a coherent subfield (Li, Y. et al., 2025; Yi et al., 2025).
MP occupies a distinct and complementary position in this landscape. Where the model-side literature asks how systems can be made more robust to interactional noise, MP asks how the human can reduce that noise at source. This is not a competing claim but a different locus of intervention: MP treats the user's interaction behaviour as a stabilisation mechanism that operates within and alongside whatever model-side robustness the deployment provides.
Several empirical findings from the model-side literature indirectly support this framing. Dongre et al. (2025) formalised context drift as a bounded stochastic process and showed that simple reminder-based interventions reliably reduce turn-wise divergence—suggesting that drift behaves as a controllable equilibrium rather than an inevitable decay. Their quantitative model is consistent with MP's procedural claim that user-side re-anchoring and stabilisation moves maintain the continuation corridor, though MP proposes a richer intervention structure (register stability, cross-layer coherence, turn geometry) than periodic re-injection alone. Whether this richer structure produces more durable stability than simple reminders is an empirical question that falls within the evaluation agenda proposed in Section 10.
The user-side strategies tested by Laban et al. (2025)—RECAP (recapitulating prior turns) and SNOWBALL (incrementally re-presenting accumulated information)—can be understood as simplified analogues of MP's compression and stabilisation moves. Their reported gains support the broader hypothesis that interaction structure matters, even when applied without the full SET framework. Among the few studies to examine human-side interaction structure directly, Flores Romero et al. (2025) found that structured turn-by-turn sequencing improved outcomes in educational human–LLM interaction—a result consistent with MP's claims, though derived from a pedagogical rather than interaction-engineering framing.
To our knowledge, existing frameworks do not yet treat user‑side interaction behaviour as a systematic, procedural stabilisation method for long‑horizon LLM work. The model-side approaches described above improve system robustness but do not address how user signalling shapes the interaction trajectory. The user-side strategies that have been tested (RECAP, SNOWBALL, scaffolded prompting) operate at the level of information delivery rather than interactional dynamics—they restructure what the user says, not how the interaction is shaped over time. MP is an attempt to fill this gap. Its contribution is not to deny the value of model-side improvements, but to identify a complementary lever—the user's signalling behaviour and interaction structure—that is available now, under current deployments, without requiring architectural changes or privileged system access.
11.3 Relationship to HCIS
Manifold Prompting and High-Coherence Interaction State (HCIS) are structurally related but not identical:
HCIS is an emergent interaction regime characterised by durable accumulation and identifiable behavioural markers (Wojewodzka, 2026).
MP is a user-side induction method: a procedural approach that increases the likelihood of entering, and sustaining, HCIS-consistent continuation.
HCIS describes what stable long-horizon interaction looks like once it holds. MP provides one practical account of how users can shape the interactional conditions under which that stability becomes more likely.
11.4 User-Side Requirements and Stabilisation Labour
A limitation of MP is that it assumes the user can perform stabilisation moves with some consistency, including:
maintaining a stable register,
issuing local, atomic corrections,
alternating expansion and compression without collapsing into resets,
linking turns reliably (loop closure) so that the interaction forms a chain rather than a stack of loosely coupled requests, and
noticing drift early enough for micro-correction to be effective.
This is best understood not as “talent” or “elite skill”, but as interactional stabilisation labour: behaviours that reduce ambiguity and preserve constraint continuity under alignment constraints. An open question is how much of this labour can be reduced through:
teaching scaffolds (lightweight guidance),
interface support (explicit constraint stacks, carry-forward cues), and
model-side stabilisation mechanisms that protect continuity without flattening expressiveness.
11.5 Model Dependence and Deployment Sensitivity
MP’s effectiveness depends on properties of deployed LLM systems, including:
strong in-context adaptation over multi-turn exchanges,
sensitivity to register and paralinguistic cues, and
the interaction between recency weighting and constraint retention.
Changes in alignment strategy, decoding policy, context handling, compression methods, or expressive tolerance can shift which manifolds are mirrorable and how durable induced stability becomes. While MP is formulated at the interaction level rather than the weight level, its empirical profile should be revalidated across models and versions, especially when deployment constraints change.
11.6 Limits of Interaction-Level Methods
MP optimises the interaction layer. It cannot, by itself:
override safety routing,
eliminate hallucination risk,
restore context after hard truncation,
guarantee factuality under uncertainty, or
fully prevent collapse under strong perturbations (e.g., safety-trigger cascades, connection resets, hard topic discontinuities).
MP can increase resilience, but it remains bounded by model stability, context continuity, and the system’s moderation and routing behaviour. This reinforces the case for complementary model-side stabilisation architectures that preserve dyadic continuity without suppressing the user’s working regime.
11.7 Generalisability Across Users and Tasks
MP is derived from interaction patterns observed in successful long-horizon dyads. Its effects may vary with:
comfort with meta-signalling,
tolerance for iterative refinement,
baseline signalling variance, and
task type (high-context vs transactional).
More empirical work is needed to determine:
whether novices can reproduce MP-consistent dynamics with minimal scaffolding,
which components are essential versus optional, and
how MP can be simplified for wider accessibility without losing the contractive mechanism.
A central question remains: is MP a broadly usable interaction scaffold, or a high-performance method whose benefits concentrate in specific communication profiles and task classes?
As it’s currently described, the protocol presupposes a degree of meta-communicative awareness that may not generalise to all user populations. Whether scaffolded or simplified versions of MP could support less experienced users is a question for future work.
11.8 Measurement and Evaluation Challenges
Many proposed observables—tone stability, referential reuse density, correction persistence, turn-geometry regularity, and loop-binding frequency—require extraction pipelines that are not yet standardised. Operationalising evaluation will require:
clear annotation guidelines,
reliable proxy definitions,
inter-rater reliability testing, and
lightweight automation where feasible.
This is primarily a tooling limitation rather than a theoretical weakness, but it constrains near-term empirical work.
11.9 Ethical and Interpretive Risks
By increasing coherence, continuity, and responsiveness, MP may amplify subjective impressions of fit—especially for users who interpret smoothness as understanding. This raises risks of:
over-attribution of comprehension,
anthropomorphic interpretation by untrained users, and
false confidence in stability when only surface fluency is present.
Mitigation should focus on framing and education: presenting MP as a procedural method, emphasising behavioural diagnostics over feeling-based inference, and keeping claims explicitly interaction-level.
A further risk is fluency-based over-trust: increased coherence and continuity can raise subjective confidence even when factual accuracy is not improved, especially if uncertainty-handling norms are not explicitly stabilised.
11.10 Summary
Manifold Prompting is an interaction-level method that:
stabilises signalling through register consistency, turn geometry, turn-linking (loop closure), and micro-correction,
supports progressive narrowing of interpretive space over time,
improves constraint persistence and reconvergence under mild perturbation, and
complements static prompt engineering in long-horizon tasks.
Its limitations—user-side stabilisation labour, deployment sensitivity, and measurement overhead—define a clear future research agenda. MP’s core contribution is not a “super prompt”, but a process model for shaping dyadic cognition through tractable, falsifiable interaction dynamics.
References
Dongre, V., Rossi, R. A., Lai, V. D., Yoon, D. S., Hakkani-Tür, D., & Bui, T. (2025). Drift no more? Context equilibria in multi-turn LLM interactions. arXiv preprint, arXiv:2510.07777.
Flores Romero, P., Fung, K. N. N., Rong, G., & Cowley, B. U. (2025). Structured human–LLM interaction design reveals exploration and exploitation dynamics in higher education content generation. npj Science of Learning, 10(1), 40.
Khalid, H. M., Jeyaganthan, A., Do, T., Fu, Y., O'Brien, S., Sharma, V., & Zhu, K. (2025). ERGO: Entropy-guided resetting for generation optimization in multi-turn language models. arXiv preprint, arXiv:2510.14077.
Laban, P., Hayashi, H., Zhou, Y., & Neville, J. (2025). LLMs get lost in multi-turn conversation. arXiv preprint, arXiv:2505.06120.
Li, Y., Shen, X., Yao, X., Ding, X., Miao, Y., Krishnan, R., & Padman, R. (2025). Beyond single-turn: A survey on multi-turn interactions with large language models. arXiv preprint, arXiv:2504.04717.
Li, Z., Lin, C., Zheng, L., Wei, W.-D., Liang, J., & Song, Q. (2025). GraphIF: Enhancing multi-turn instruction following for large language models with relation graph prompt. arXiv preprint, arXiv:2511.10051.
Liu, G., Zhu, F., Feng, R., Ma, C., Wang, S., & Meng, G. (2026). Intent mismatch causes LLMs to get lost in multi-turn conversation. arXiv preprint, arXiv:2602.07338.
Sarkar, R., Sarrafzadeh, B., Chandrasekaran, N., Rangan, N., Resnik, P., Yang, L., & Jauhar, S. K. (2025). Conversational user–AI intervention: A study on prompt rewriting for improved LLM response generation. arXiv preprint, arXiv:2503.16789.
Wei, Q., Zeng, S., Li, C., Brown, W., Frunza, O., Deng, W., Schneider, A., Nevmyvaka, Y., Zhao, Y. K., Garcia, A., & Hong, M. (2025). Reinforcing multi-turn reasoning in LLM agents via turn-level reward design. arXiv preprint, arXiv:2505.11821.
Wojewodzka, A. (2026). High-coherence interaction state (Third Space) as an interactional regime in human–LLM dyads (v1.1). Zenodo. 10.5281/zenodo.18130087
Yi, Z., Ouyang, J., Xu, Z., Liu, Y., Liao, T., Luo, H., & Shen, Y. (2025). A survey on recent advances in LLM-based multi-turn dialogue systems. arXiv preprint, arXiv:2402.18013